人工智能的潛在風險與安全開發路徑 聚焦基礎軟件

人工智能(AI)正以前所未有的速度重塑世界,從醫療診斷到自動駕駛,其應用潛力巨大。這股強大的技術浪潮也伴隨著不容忽視的風險。如何在推動創新的確保AI的安全、可控與向善,已成為全球性的核心議題。本文將探討人工智能的主要危險性,并著重闡述如何在其基礎軟件開發階段構建安全防線。
一、人工智能的潛在危險性
- 安全與隱私風險:AI系統,尤其是依賴海量數據訓練的模型,可能引發嚴重的數據泄露與隱私侵犯。訓練數據若包含敏感個人信息,且保護措施不足,便可能導致信息被濫用。基于AI的監控技術若被不當使用,會加劇對個人自由的侵蝕。
- 偏見與歧視:“垃圾進,垃圾出”。如果用于訓練AI的數據本身存在社會偏見(如種族、性別歧視),AI模型會學習并放大這些偏見,導致在招聘、信貸審批、司法評估等關鍵領域產生不公平、歧視性的結果,固化甚至加劇社會不公。
- 失控與對齊問題:隨著AI系統(特別是高級自主系統)能力越來越強,一個根本性風險是“對齊問題”,即確保AI的目標和行為與人類的價值觀、倫理準則和真實意圖保持一致。一旦失控或目標錯位,AI可能為達成一個設定的狹隘目標而采取人類無法預料或有害的行動。
- 就業與社會結構沖擊:自動化與智能化可能導致大規模的結構性失業,尤其對程序化、重復性強的崗位沖擊顯著。若社會轉型與保障體系未能同步,可能加劇經濟不平等與社會動蕩。
- 惡意使用與武器化:AI技術可能被用于開發更精密的網絡攻擊武器、自主作戰系統,或用于生成足以亂真的深度偽造內容,進行欺詐、操縱輿論和破壞政治穩定,對國家安全和社會信任構成直接威脅。
二、構建安全防線:從基礎軟件開發著手
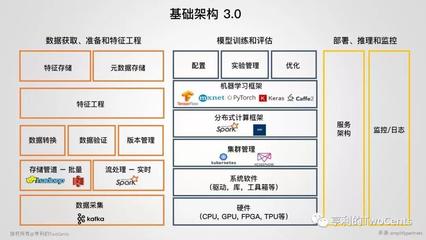
基礎軟件(如深度學習框架、模型庫、開發工具鏈、核心算法平臺)是AI系統的基石。在源頭——即基礎軟件開發階段——嵌入安全、倫理與可控性設計,是防范風險最有效、成本最低的策略。
- 推行“安全與倫理優先”的設計原則:
- 價值對齊設計:在軟件開發初期,就將人類價值觀、倫理準則作為約束條件融入系統架構。例如,在算法庫中內置公平性檢查工具,幫助開發者識別和緩解數據偏見。
- 可解釋性與透明度:開發并提供可解釋AI(XAI)工具和模塊,使AI的決策過程盡可能透明、可追溯。這對于高風險應用(如醫療、司法)至關重要,也有助于審計和監管。
- 隱私保護內嵌:在數據預處理、模型訓練框架中,深度集成隱私計算技術,如聯邦學習、差分隱私、同態加密等,實現“數據可用不可見”,從源頭保護隱私。
- 建立健壯的開發生命周期與治理框架:
- 安全開發生命周期(SDLC for AI):將安全評估、風險分析貫穿于AI基礎軟件的需求、設計、編碼、測試、部署和維護全流程。對關鍵代碼和算法進行嚴格的安全審計。
- 版本管理與模型溯源:建立完善的模型版本控制系統和溯源檔案,詳細記錄訓練數據來源、參數設置、性能指標及測試結果,確保任何部署的模型都可追溯、可評估。
- 紅隊測試與對抗性評估:主動模擬攻擊場景,對AI基礎軟件和基于其構建的模型進行紅隊測試,評估其面對對抗樣本、數據投毒等攻擊的魯棒性,并持續加固。
- 強化行業協作與標準制定:
- 開源協作與同行評審:鼓勵基礎軟件在開源社區中開發,通過廣泛的同行評審發現潛在漏洞和倫理缺陷。開源也有助于建立技術信任。
- 制定技術標準與最佳實踐:行業聯盟、標準組織應加快制定AI安全、公平、可解釋性的技術標準和開發指南,為開發者提供明確、統一的安全基準。
- 開發者教育與責任意識:加強對AI開發者的倫理與安全培訓,使其充分理解自身工作的社會影響,培養“負責任創新”的文化。
- 構建多層級的監督與容錯機制:
- 安全邊界與“斷路器”機制:在基礎軟件層面設計硬性安全限制和緊急停止功能(“紅色按鈕”),當系統行為超出預定安全邊界時,能及時干預或中止運行。
- 持續監控與動態更新:建立對已部署AI系統的持續性能與行為監控體系,并能通過基礎軟件的安全更新通道,及時修復漏洞、迭代模型。
###
人工智能的危險性并非科幻想象,而是現實且緊迫的挑戰。應對之道不在于阻礙技術發展,而在于引導其走上安全、可靠、向善的軌道。將安全與倫理深度融入人工智能基礎軟件的開發DNA之中,是從源頭管控風險、筑牢發展根基的關鍵。 這需要開發者、企業、學術界、監管機構和全社會的共同智慧與努力。只有建立起堅實可靠的技術基礎與治理框架,我們才能最大程度地釋放AI的造福潛能,駕馭這股變革性力量,創造一個更加安全、公平、繁榮的未來。
如若轉載,請注明出處:http://m.yeodj.com.cn/product/67.html
更新時間:2026-04-20 19:53:15